 一般般帅
一般般帅认识Prometheus
前言:这次来稍微系统性地认识一下Prometheus。注意,本篇不是小白类的知识普及类文章,要求读者对Prometheus有一定的知识积累和认识深度,另外一些点不会详细展开,需要读者自行深挖。
一、产品介绍
1、概述
Promehteus是一款近年来非常火热的容器监控系统,它使用go语言开发,设计思路来源于Google的Borgmom(一个监控容器平台的系统)。产品由前谷歌SRE Matt T.Proudd发起开发,并在其加入SoundCloud公司后,与另一位工程师Julius Volz合伙推出,将其开源发布。
2016年,由Google发起的原生云基金会(Cloud Native Computing Foundation)将Prometheus纳入麾下,成为该基金会继Kubernetes后第二大开源项目。
Promehteus天然具有对容器的适配性,可非常方便的满足容器的监控需求,也可用来监控传统资源。近年来随着kubernetes容器平台的火爆,Prometheus的热度也在不断上升,大有超越老牌监控系统Zabbix成为No.1的趋势,目前已在众多公司得到广泛的使用。
2、Prometheus的特点
-
多维度数据模型
-
灵活的查询语言
-
不依赖分布式存储,单个服务器节点是自主的
-
通过基于HTTP的pull方式采集时序数据
-
可以通过中间网关进行数据推送
-
通过服务发现或者静态配置来发现目标服务对象
-
支持多种多样的图表和界面展示,比如Grafana 等
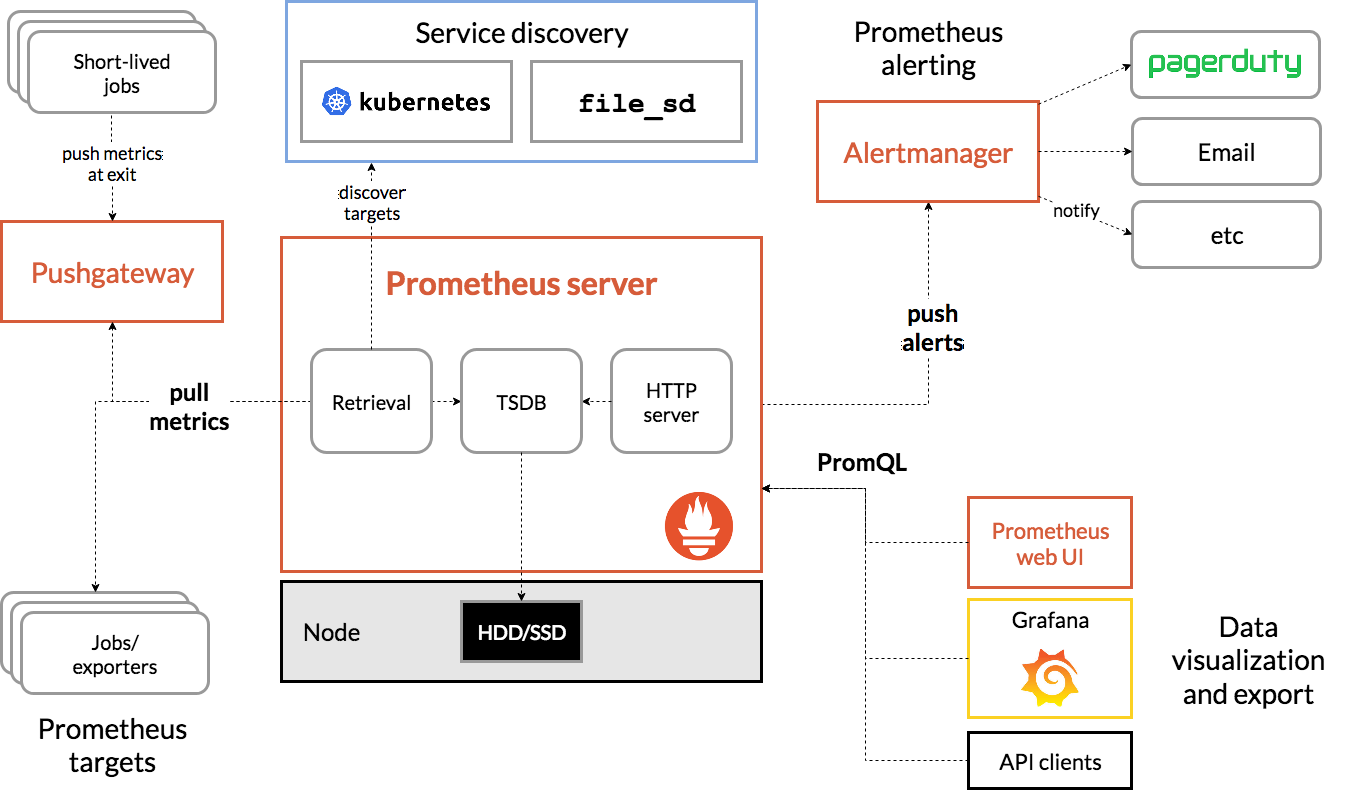
3、Prometheus相关组件
-
Prmoetheus Server:服务端,用于处理和存储监控数据。
-
Exporter:监控客户端,用于收集各类监控数据,不同的监控需求由不同的exporter处理,如node-exporter、mysql-exporter、blackbox-exporter等。
-
Pushgateway:在不支持pull 拉取监控数据的场景中,可通过部署Pushgateway的方式,由监控源主动上报到Promtehus。
-
Alertmanager:独立组件,用于处理告警信息。
-
Web-UI:Pometheus自带的web界面,可进行监控数据的展示与查询。
-
其他支持工具:Promethues项目本身提供的组件及丰富的开源工具和套件。
官方架构图:
二、数据类型
Prometheus的时序数据分为Counter(计数器),Gauge(仪表盘),Histogram(直方图),Summary(摘要)四种类型。
1、Counter类型
Counter 英[ˈkaʊntə(r)] 类型的指标与计数器一样,会按照某个趋势一直变化(一般是增加),我们往往用它记录服务请求总量、错误总数等。
基于counter类型的数据,我们可以清楚某些事件发生的次数,由于数据是以时序的方式进行存储,我们也可以轻松了解该事件产生的速率变化。

例如,通过rate()函数,获取日志每分钟的增长率QPS。
rate(logback_events_total[1m])
2、Gauge类型
Gauge 英[ɡeɪdʒ] 类型的指标用于展示瞬时的值,与时间没有关系,可增可减。该类型值可用来记录CPU使用率、内存使用率等参数,用来反映目标在某个时间点的状态。
以下是一个关于内存使用量的数据展示,可以看到每个时间点的数据具有随机性,不与其他数据有关联。
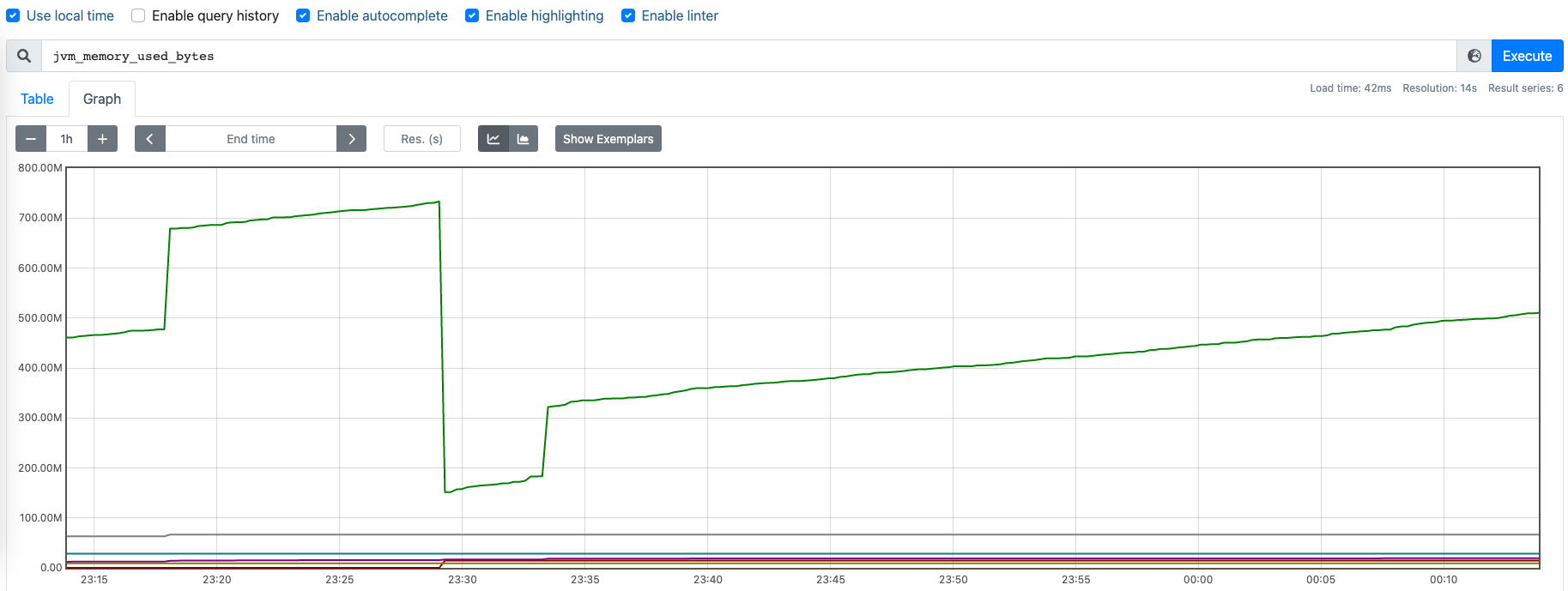
Gauge指标简单且易于理解,对于该类型的指标,我们可以直观的查看目标在当前的状态。
3、Histogram类型
假设某个接口一分钟内的请求为1万次,采用平均值的方式计算出响应时间为2s,通过该值我们无法判断是所有请求都不超过2s,还是有部分较高延迟被平均值拉低,该方法缺乏对于全局的观察性。对此,Prometheus通过Summary和Histogram类型来解决这样的问题。
Histogram 英[ˈhɪstəɡræm]类型会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的 bucket(存储桶)中 ,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
Prometheus 取值间隔的划分采用的是累积区间间隔机制,即每个 bucket 中的样本均包含了其前面所有 bucket 中的样本,因而也称为累积直方图。
Histogram 类型的每个指标有一个基础指标名称 ,它会提供多个时间序列:
-
_sum :所有样本值的总和
-
_count :总的采样次数,它自身本质上是一个 Counter 类型的指标
-
_bucket{le=“<上边界>”} :观测桶的上边界,即样本统计区间,表示样本值小于等于上边界的所有样本数量
-
_bucket{le=“+Inf”} :最大区间(包含所有样本)的样本数量
如下图:

# 其中所有样本值的大小总和,命名为 _sum,这里可以理解为请求总耗时为10.10s
prometheus_http_request_duration_seconds_sum{handler="/metrics"} 10.107670803000001
# 样本总数,命名为 _count ,效果与 _bucket{le=“+Inf”} 相同
prometheus_http_request_duration_seconds_count{handler="/metrics"} 20
Histogram可用于请求耗时、响应时间等数据的统计,例如指标prometheus_http_request_duration_seconds_bucket即为Histogram类型。
Histogram 在客户端仅是简单的桶划分和分桶计数,分位数计算由 Prometheus Server 基于样本数据进行估算,因而其结果未必准确,甚至不合理的 bucket 划分会导致较大的误差。
4、Summary类型
Summary 英[ˈsʌməri] 类型的指标通过计算分位数(quantile)显示指标结果,可用于统计一段时间内数据采样结果 ,如中位数(quantile=0.5)、9分位数(quantile=0.9)等。
Summary 是一种类似于 Histogram 的指标类型,但它在客户端于一段时间内(默认为 10 分钟)的每个采样点进行统计,计算并存储了分位数数值,Server 端直接抓取相应值即可。
示例:
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server进行 wal_fsync 操作的总次数为 216 次,耗时 2.888716127000002s。 其中中位数(quantile=0.5)的耗时为 0.012352463s,9分位数(quantile=0.9)的耗时为0.014458005s。
三、PromQL语法
PromQL是Prometheus内置的数据查询DSL(Domain Specific Language)语言,其提供对时间序列丰富的查询功能,聚合以及逻辑运算能力的支持。当前,PromQL被广泛应用在Prometheus的日常使用中,包括数据查询、可视化、告警处理等,可以说,掌握PromQL是熟练使用prometheus的必备条件。
1、操作符
PromQL支持的所有数学运算符如下:
- +(加法)
- -(减法)
- *(乘法)
- / (除法)
- %(求余)
- ^(幂运算)
Prometheus支持的比较运算符如下:
- ==(相等)
- !=(不相等)
- >(大于)
- <(小于)
- >= (大于等于)
- <= (小于等于)
Prometheus支持的逻辑运算符如下:
- and(并集)
- or(交集)
- unless(排除)
2、内置函数
Prometheus内置不少函数,通过灵活的应用这些函数,可以更方便的查询及数据格式化。本文将选取其中较常使用到的几个函数进行讲解。
- ceil 函数
ceil函数会将返回结果的值向上取整数。示例:
ceil(avg(prometheus_http_requests_total{code="200"}))
- floor函数
floor 函数与ceil相反,将会进行向下取整的操作。示例:
floor(avg(prometheus_http_requests_total{code="200"}))
- rate函数
rate函数是使用频率最高,也是最重要的函数之一。rate用于取某个时间区间内每秒的平均增量数,它会以该时间区间内的所有数据点进行统计。rate函数通常作用于Counter类型的指标,用于了解增量情况。
# irate取的是在指定时间范围内的最近两个数据点来算速率
# 而rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果。
# 所以官网文档说:irate适合快速变化的计数器(counter),而rate适合缓慢变化的计数器(counter)
rate(prometheus_http_requests_total{handler="/rules"}[1m])
- irate函数
相比rate函数,irate提供了更高的灵敏度。irate函数是通过时间区间中最后两个样本数据来计算区间向量的增长速率,从而避免范围内的平均值拉低峰值的情况。
irate(prometheus_http_requests_total{handler="/rules"}[1m])
- 其它内置函数
除了上面提到的这些函数外,PromQL还提供了大量的其他函数供使用,功能范围涵盖了日常所需的功能,如用于标签替换的label_replace函数、统计Histogram指标分位数的histogram_quantile函数,更多信息可参阅官方文档:https://prometheus.io/docs/prometheus/latest/querying/functions/。
histogram_quantile(0.95, rate(histogram_showcase_metric_bucket[1m]))
3、基础查询
Prometheus的基础查询一般表达格式为<metric name>{label=value},通过指标名称加标签的方式进行查询,如查看Prometheus更新接口的请求次数。
# 查询 url=/test,且code!= 200的指标数据
http_api_request_seconds_count{url="/test", code!="200"}
# 什么都不加也行
http_api_request_seconds_count
除了使用完全匹配的方式的进行查询外,PromQL还支持使用正则表达式作为匹配条件,书写格式为label =~regx,其中~为表示符,regx为正则内容。
# 模糊匹配url以reload结尾的指标
http_api_request_seconds_count{url=~"*test"}
# 反向匹配
http_api_request_seconds_count{url=!~"*test"}
# 匹配多项
http_api_request_seconds_count{url=~"/graph|/rules|/metrics"}
4、时间范围查询
在上述的基础查询案例中, 我们通过<metric name>{label=value}方式进行查询时,返回结果中只会包含该时间序列的最新一个值,这样的结果类型称为瞬时向量(instant vector )。除了瞬时向量,PromQL也支持返回时间序列在某个时间范围内的一组数据,这种称为范围向量(range vector )。
范围向量表达式需要定义时间选择的范围,时间范围被包含在[]号中,例如查询5分钟内的样本数据,可用下列表达式
# 相当于把数据按照每5分钟分成一个小组,非必要这个刻度不建议调得很大,会损失精度
# 这里直接查询报错 invalid expression type "range vector" for range query, must be Scalar or instant Vector
# 范围向量选择器的返回是范围向量型数据,它不能用于表达式浏览器中图形绘制功能,事实上范围向量选择几乎都是结合速率类的rate函数一同使用
# 需要叠加一个非聚合函数 如 rate irate delta idelta sum 等
# 且时间范围不能低于采集间隔,这里5m如果是5s,那么也不会有值
http_api_request_seconds_count{url=~"/graph|/rules|/metrics"}[5m]
# 正例
rate(http_api_request_seconds_count{url=~"/graph|/rules|/metrics"}[5m])
在时间序列的查询上,除了以当前时间为基准,也可以使用offset进行时间位移的操作。如以1小时前的时间点为基准,查询瞬时向量和5分钟内的范围向量:
# 以1小时前的时间点为基准
http_api_request_seconds_count offset 1h
5、聚合操作
PromQL语言提供了不少内置的聚合操作符,用于对瞬时向量的样本进行聚合操作 ,形成一个新的序列。目前支持的聚合操作符如下:
-
sum (求和)
-
min (最小值)
-
max (最大值)
-
avg (平均值)
-
stddev (标准差)
-
stdvar (标准方差)
-
count (计数)
-
count_values (对value进行计数)
-
bottomk (后n条时序)
-
topk (前n条时序)
-
quantile (分位数)
# 计算所有接口的请求数量总和
sum(prometheus_http_requests_total{})
# 匹配其中样本值为最大的时间序列
max(prometheus_http_requests_total{})
# 求出所有样本的平均值
avg(prometheus_http_requests_total{})
# 显示匹配的前N条时间序列数据
topk (5,prometheus_http_requests_total{})
在聚合操作中,还可以在表达式中加上without或 by ,其中without用于在计算样本中移除列举的标签,而by正相反,结果向量中只保留列出的标签,其余标签则移除。
sum(prometheus_http_requests_total{}) without (code,handler,job)
sum(prometheus_http_requests_total{}) by (instance)
四、指标监控
以下示例只作演示使用,不作为实际参考。Spring监控指标详解可以参考这里:https://cloud.tencent.com/developer/article/2244572
1、JVM监控项详解
Spring Boot中的Actuator模块默认采用Micormeter来收集指标(比如JVM、系统CPU/内存/load、Tomcat等),并通过上报到Prometheus监控系统中,以暴露出我们需要的一些关键的系统指标数据。下面简单列了下常用的一些指标
# 1 counter 记录到日志的错误级别事件数 关键类 LogbackMetricsAutoConfiguration
logback_events_total
# 2 gauge 整个系统的“最近cpu使用情况” 关键类 SystemMetricsAutoConfiguration 下同
system_cpu_usage
# 3 gauge java虚拟机进程的“最近CPU使用”
process_cpu_usage
# 4 gauge 系统负载
system_load_average_1m
# 5 gauge java虚拟机可用的处理器数量
system_cpu_count
# 6 gauge 自unix时代以来进程的开始时间(秒)
process_start_time_seconds
# 7 gauge java虚拟机的运行时间
process_uptime_seconds
# 8 gauge 打开文件描述符数量
process_files_open_files
# 9 gauge 最大文件描述符数量
process_files_max_files
# 10 counter tomcat过期会话数总计 关键类 TomcatMetricsAutoConfiguration 下同
tomcat_sessions_expired_sessions_total
# 11 counter tomcat拒绝会话数总计
tomcat_sessions_rejected_sessions_total
# 12 gauge tomcat_活跃会话最大数量
tomcat_sessions_active_max_sessions
# 13 counter tomcat会话创建会话总数
tomcat_sessions_created_sessions_total
# 14 gauge tomcat当前活跃会话数
tomcat_sessions_active_current_sessions
# 15 gauge 最大tomcat会话存活时间
tomcat_sessions_alive_max_seconds
# 16 gauge Java虚拟机中当前加载的类数 关键类 JvmMetricsAutoConfiguration 下同
jvm_classes_loaded_classes
# 17 counter 未加载的classes数
jvm_classes_unloaded_classes_total
# 18 gauge jvm内存使用大小
jvm_memory_used_bytes
# 19 gauge 可用于内存管理的字节的最大内存量
jvm_memory_max_bytes
# 20 gauge 提交给Java虚拟机使用的内存量(字节)
jvm_memory_committed_bytes
# 21 gauge JVM缓冲区已用内存
jvm_buffer_memory_used_bytes
# 22 gauge 缓冲区的总容量的估计
jvm_buffer_total_capacity_bytes
# 23 gauge 当前缓冲区数
jvm_buffer_count_buffers
# 24 summary GC暂停时间
jvm_gc_pause_seconds
# 25 gauge GC最大暂停时间
jvm_gc_pause_seconds_max
# 26 gauge 老年代内存池的最大大小
jvm_gc_max_data_size_bytes
# 27 counter 在一次GC之后到下一次GC之前,年轻一代内存池的大小增加
jvm_gc_memory_allocated_bytes_total
# 28 gauge full GC后的老年代内存池大小
jvm_gc_live_data_size_bytes
# 29 counter 从GC之前到GC之后老年代内存池大小正增长的计数
jvm_gc_memory_promoted_bytes_total
# 30 gauge 当前处于各状态的线程数
jvm_threads_states_threads
# 31 gauge 当前活动线程数,包括守护进程线程和非守护进程线程
jvm_threads_live_threads
# 32 gauge 当前守护进程线程的数量
jvm_threads_daemon_threads
# 33 gauge JVM峰值线程数
jvm_threads_peak_threads
# 34 summary http请求调用情况
# 关键类 WebMvcMetricsAutoConfiguration#webMvcMetricsFilter#request.getMetricName
# 也可以看下 WebMvcMetricsFilter,有了这个数据,后续就可以做P90 P95 P99 RT QPS 同比环比等针对url接口级别的统计分析
http_server_requests_seconds
# 35 gauge http请求调用最大耗时
http_server_requests_seconds_max
下面将会针对现实生活中可能遇到的一些情况,进行下实际PromQL演示(这里顺便推荐一下grafana面板4701)。
2、常用PromQL
# 查看system cpu使用率
system_cpu_usage * 100
# 查看user process使用率
system_cpu_usage * 100
# 查看堆内存变化
jvm_memory_used_bytes
# 查看gc次数,注意jvm_gc_pause_seconds是summary类型,有_count、_sum、_max结尾三种形式
jvm_gc_pause_seconds_count
# 查看gc耗时
jvm_gc_pause_seconds_sum/jvm_gc_pause_seconds_count
# 查看线程状态
jvm_threads_states_threads
# 查看url次数增长,注意 spring内置的是 http_server_requests_seconds_count
# 这里是自己埋的,两者大致等价
http_api_request_seconds_count
# 查看url区段增量,30s为一个小区间
increase(http_api_request_seconds_count[30s])
# 查看url qps变化 irate将为精准一下
irate(http_api_request_seconds_count[30s])
# 查看url在一段时间内的调用总和,24h代表一天,1h代表一天
sum(increase(http_api_request_seconds_count[1h]))
# 同比 环比 offset 1d可以简单理解为同比 1w可以简单理解为环比,不加offset即当前值
sum(increase(http_api_request_seconds_count[1h] offset 1d))
sum(increase(http_api_request_seconds_count[1h] offset 1w))
irate(http_api_request_seconds_count[1h] offset 1d)
irate(http_api_request_seconds_count[1h] offset 1w)
# 统计接口平均耗时RT,计算公式 RT = 单位时间内总耗时 / 单位时间内总次数
# 参考链接 https://prometheus.io/docs/practices/histograms/#errors-of-quantile-estimation
rate(http_api_request_seconds_sum[1m]) / rate(http_api_request_seconds_count[1m])
# 最大耗时RT,直接读取max值就行
sum(http_api_request_seconds_max)
# P99 P95 P90 P50,注意并不是所有格式都可以看P95,一般常用于响应时间RT
# 注意这里的P95只能反映第95%个点落在相应的bucket中,并不能说明95%的请求都是这个耗时
histogram_quantile(0.95, sum(rate(http_api_request_seconds_bucket[1m])) by (le))
histogram_quantile(0.99, sum(rate(http_api_request_seconds_bucket[1m])) by (le))
histogram_quantile(0.90, sum(rate(http_api_request_seconds_bucket[1m])) by (le))
# 查看上下游调用情况,这里只是简单举例
rate(http_api_request_seconds_count{downstream='aa', upstream='bb'}[30s])
3、prometheus接口
这里列举下比较常用的/query、/query_range接口,官方文档:https://prometheus.io/docs/prometheus/latest/querying/api/#range-queries。
1、query接口
接口功能:即使数据查询,将根据表达式返回单个时间点的数据
接口地址:/api/v1/query,同时支持get和post。
接口入参:
- query:Prometheus表达式查询字符串,必填。
- time:评估时间戳,可选参数,默认使用当前服务器时间。
- timeout:查询超时时间,可选参数,默认使用-query.timeout的全局参数。
请求示例:
# 时间戳转换网站 https://www.beijing-time.org/shijianchuo/
# 时间为unix格式,1685885129 大致等于 2023-06-04 21:25:29
curl 'http://localhost:19090/api/v1/query?query=http_api_request_seconds_count&time=1685885129'
# 应答串
{
"status": "success",
"data": {
"resultType": "vector",
"result": [{
"metric": {
"__name__": "http_api_request_seconds_count",
"http_appid": "baihu-app-svc",
"http_data_type": "base",
"http_env": "dev",
"http_ip": "192.168.0.104",
"http_metric_type": "histogram",
"instance": "host.docker.internal:2023",
"job": "spring_boot",
"ret": "-",
"route": "/noLog",
"status": "200"
},
"value": [1685885129, "36648"]
}]
}
}
2、query_range接口
接口功能:范围数据查询,将根据表达式返回指定时间范围内的数据
接口地址:/api/v1/query_range,同时支持get和post。
接口入参:
- query:Prometheus表达式查询字符串,必填。
- start:开始时间戳,包括在内
- end:结束时间戳,包括在内
- step:以格式或浮点秒数查询分辨率步长,如60s
- timeout:查询超时时间,可选参数,默认使用-query.timeout的全局参数。
请求示例:
# 1685885400 = 2023-06-04 21:30:00
# 1685886600 = 2023-06-04 21:50:00
# 1685721600 = 2023-06-03 00:00:00
# 1685808000 = 2023-06-04 00:00:00
# 1685894400 = 2023-06-05 00:00:00
curl 'http://localhost:19090/api/v1/query_range?query=sum(increase(http_api_request_seconds_count[30s]))&start=1685721600&end=1685894400&step=1h'
# 应答串
# 时间戳依次为 2023-6-3 22:0:0、2023-6-3 23:0:0、2023-6-4 0:0:0、2023-6-4 3:0:0
# 2023-6-4 4:0:0、2023-6-4 11:0:0、2023-6-4 21:0:0、2023-6-4 22:0:0
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [{
"metric": {},
"values": [
[1685800800, "1144.0762717514501"],
[1685804400, "1143.923738417439"],
[1685808000, "1104"],
[1685818800, "1088.681716619154"],
[1685822400, "826.1652330466093"],
[1685847600, "957.9361375908272"],
[1685883600, "1146.076405093673"],
[1685887200, "1103.705678485737"]
]
}]
}
}
3、reload接口
curl -XPOST http://localhost:19090/-/reload ,可以通过调用此接口让Prometheus重新加载配置。
五、监控告警
在Prometheus的架构中,告警功能由Prometheus Server和Alertmanager 协同完成,Prometheus Server负责收集目标实例的指标,定义告警规则以及产生警报,并将相关的警报信息发送到Alertmanager。
Alertmanager则负责对告警信息进行管理 ,根据配置的接收人信息,将告警发送到对应的接收人与介质。
这里普及一下监控系统的黄金四指标:延迟、流量、错误、饱和度。简单一点,可以大致理解为:QPS、RT、Exception、CPU、Memory。
1、告警规则
Prometheus的警报有如下几种状态:
-
Inactive:警报未被触发。
-
Pending:警报已被触发,但还未满足for参数定义的持续时间。
-
Firing:警报被触发警,并满足for定义的持续时间的。此时Prometheus会将相关的告警信息转发到Alertmanager,并由其进行告警信息的发送。
对于告警规则的具体格式,这里不做详细说明。如下是几个可供参考的文件实例:
prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- host.docker.internal:19093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/prometheus/rules/*rules.yml"
recording_rules.yml
# 记录规则文件,不定义具体的告警规则
groups:
- name: node-exporter-record
rules:
- expr: up{job=~"node-exporter"} # 告警表达式
record: node_exporter:up # 告警表达式简化版
labels: # 自定义标签
desc: "节点是否在线, 在线1,不在线0"
unit: " "
job: "node-exporter"
- expr: (1 - avg by (instance) (irate(node_cpu_seconds_total{job="node-exporter",mode="idle"}[1m]))) * 100
record: node_exporter:cpu:total:percent
labels:
desc: "节点的cpu总消耗百分比"
unit: "%"
job: "node-exporter"
- expr: node_memory_MemTotal_bytes{job="node-exporter"} - node_memory_MemFree_bytes{job="node-exporter"}
record: node_exporter:memory:used
labels:
desc: "节点的已使用内存量"
unit: byte
job: "node-exporter"
- expr: (1-(node_memory_MemAvailable_bytes{job="node-exporter"} / (node_memory_MemTotal_bytes{job="node-exporter"})))* 100
record: node_exporter:memory:used:percent
labels:
desc: "节点的内存使用百分比"
unit: "%"
job: "node-exporter"
custom_rules.yml
# 黄金四指标:QPS、RT、Exception、CPU、Memory
# 一般来说,exc cpu峰值是60% pod cpu峰值是40%,具体看服务的运行情况
############### node-exporter 相关指标监控 ###############
groups:
- name: node-exporter
rules:
# 告警规则的名称,在每一个group中,规则名称必须是唯一的
- alert: "1.CPU使用率大于60%,持续2分钟"
# 基于PromQL表达式配置的规则条件,用于计算相关的时间序列指标是否满足规则
expr: node_exporter:cpu:total:percent >= 60
# 持续时间
for: 2m
# 自定义标签, 允许用户指定要添加到告警信息上的一组附加标签
labels:
level: warn
# 用于指定一组附加信息,如用于描述告警的信息文字等,本示例中summary用于描述主要信息,description用于描述详细的告警内容
annotations:
description: "instance = {{$labels.instance}} system cpu is too high, current value = {{$value}}"
summary: "cpu usage is too high"
- alert: "2.node-exporter下线,持续时间2分钟"
expr: node_exporter:up != 1
for: 2m
labels:
level: warn
annotations:
description: "The node is Down more than 2 minute!"
summary: "The node is down"
- alert: "3.内存使用率超过70%,持续时间2分钟"
expr: node_exporter:memory:used:percent > 70
for: 2m
labels:
level: warn
annotations:
description: "instance = {{$labels.instance}} system memory is too high, current value = {{$value}}"
summary: "memory usage is too high"
############### Java服务 相关指标监控 ###############
- name: spring_boot
rules:
- alert: "4.服务器QPS大于20,持续时间2分钟"
expr: irate(http_api_request_seconds_count[1m]) >= 20
for: 2m
labels:
level: warn
annotations:
description: "instance = {{$labels.instance}} sever qps is too high, current value = {{$value}}"
summary: "sever qps is too high"
############### 省略其他 ###############
关于告警规则的讲解,大概就到这里了。在配置好规则文件之后,可以通过查看容器日志命令观察规则文件是否生效,还可以通过Prometheus自带的Alerts界面进行规则的查看。
2、告警管理
AlertManagerr集成报警系统的几个重要功能:
- 分组: 可以通过route书的group_by来进行报警的分组,多条消息一起发送。
- 抑制: 重要报警抑制低级别报警(inhibit_rules配置)。
- 静默: 故障静默,确保在接下来的时间内不会在收到同样报警信息(需要通过web界面)。
AlertManager默认端口是9093,自带管理界面。同上,这里也以一个配置文件作简要说明:
# 主界面地址:http://localhost:19093/#/alerts
# 这里只以 email 为例,但还支持微信、钉钉、webhook
# 通知模板官网链接:https://prometheus.io/docs/alerting/latest/notifications/
# route路由是一个基于标签匹配规则的树状结构,所有的告警信息都会从配置中的顶级路由(route)进入路由树。
# 从顶级路由开始,根据路由规则中的match或者match_re来匹配进入到不同的子路由,并且根据子路由设置的接收者发送告警。
# 如果所有route信息都没法命中,就采用默认的receiver这个配置来发送消息
global:
resolve_timeout: 5m # 定义持续多长时间未接收到告警标记后,就将告警状态标记为resolved
smtp_from: 'xxx@163.com' # 发件人
smtp_smarthost: 'smtp.163.com:25' # 邮箱服务器的 POP3/SMTP 主机配置 smtp.qq.com 端口为 465 或 587
smtp_auth_username: 'xxx@163.com' # 用户名
smtp_auth_password: 'xxx' # 授权码
smtp_require_tls: true
templates: # 指定告警通知时的模板
- '/etc/prometheus/alertmanager/template/*.tmpl'
route: # 用于定义Alertmanager接收警报的处理方式,根据规则进行匹配并采取相应的操作
group_by: ['alertname'] # 告警分组
group_wait: 5s # 在组内等待所配置的时间,如果同组内,5 秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5 分钟后发送。
repeat_interval: 5m # 发送告警间隔时间 s/m/h,如果指定时间内没有修复,则重新发送告警
receiver: 'email' # 优先使用 wechat 发送
routes: #子路由,使用 email 发送
- receiver: email
match_re:
serverity: email
receivers:
- name: 'email'
email_configs:
- to: '3292028193@qq.com' # 如果想发送多个人就以 ',' 做分割
send_resolved: true
html: '{{ template "email.html" . }}'
# 邮件主题信息
headers: {Subject: "[WARN] 报警邮件 {{ .CommonLabels.instance }} {{ .CommonAnnotations.summary }}"}
未完待续,敬请期待....